
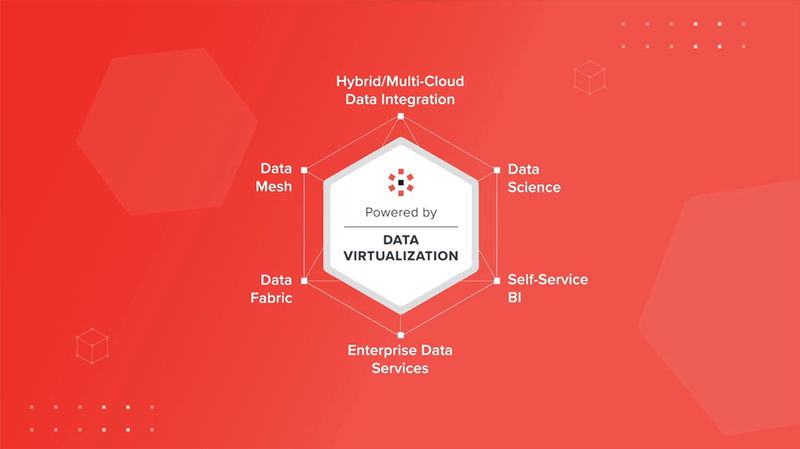




データの需要が高まるにつれ、組織はデータ エンジニアリングの取り組みを加速して価値実現までの時間を短縮する必要があります。現在のほとんどのアプローチは時間がかかりすぎ、コストがかかり、見直しが発生し、データの不整合が生じる可能性があります。これに対して、データ仮想化は、データ製品を迅速に作成するためのアジャイルなアプローチを提供します。データ仮想化では、データ製品を一元的に管理し、複製せずに利用者に提供することができます。データ仮想化は、最新の分散型データアーキテクチャとユースケースの優れた基盤となります。
データアーキテクト
データ仮想化は、データ統合の柔軟性を高め、データアーキテクトが最新のデータ技術やイノベーションを最大限に活用して、データ戦略やアーキテクチャを成功裏に進化させるのに役立ちます。
データエンジニア
データ仮想化は習得が容易であり、使用すると非常に生産性が高く、データエンジニアがより多くのデータビューをより速く提供できるため、より早くビジネス価値を実現できます。
データサイエンティストとアナリスト
データ仮想化は、データサイエンティストやアナリストが必要なすべてのデータに、希望する方法で即座にアクセスできるようにします。
アナリティクスリーダー
データ仮想化は、分析やアプリケーションを支えるために必要なデータへのアクセスを簡素化し、加速します。
CIOおよびCTO
データ仮想化のアジャイルな統合アプローチにより、CIO と CTO は、より少ない投資で、刻々と変化するビジネス ニーズに、より迅速に対応できるようになります。
データスチュワード
データ仮想化は、データスチュワードがエンタープライズデータモデルと標準を実装し、遵守させるのを支援し、一貫性のある、安全な、ガバナンスされたデータを提供します。



